The opportunity in Software 3.0 is not simply that AI can help us write more code. The opportunity is that we can rethink how software systems are designed, operated, evaluated, and improved.
The visible change is speed. AI can generate code, summarize systems, scaffold applications, and assist developers faster than before.
The deeper change is control.
We are moving from systems where humans specify behavior directly to systems where humans shape behavior through context, tools, memory, examples, evaluations, guardrails, and feedback loops.
That shift requires more than clever prompts.

It requires engineering leadership.
Andrej Karpathy describes this transition as Software 3.0: a world where large language models become a new programmable layer for digital work. In his framing, Software 1.0 is explicit code, Software 2.0 is learned model weights, and Software 3.0 is programming LLMs through prompts, context, tools, examples, memory, and instructions. He also distinguishes “vibe coding” from “agentic engineering,” where the professional challenge is coordinating fallible agents while preserving correctness, security, taste, and maintainability (Karpathy, 2026).
For engineering leaders, the implication is clear: Software 3.0 is not just about AI writing code. It is about designing the operating model around AI systems that can reason, act, fail, recover, and improve.
Software 1.0: Humans Write the Rules
Software 1.0 is the world most engineering organizations already understand.
A human analyzes the problem, designs the logic, writes source code, compiles or deploys it, and the application behaves according to those explicit instructions.
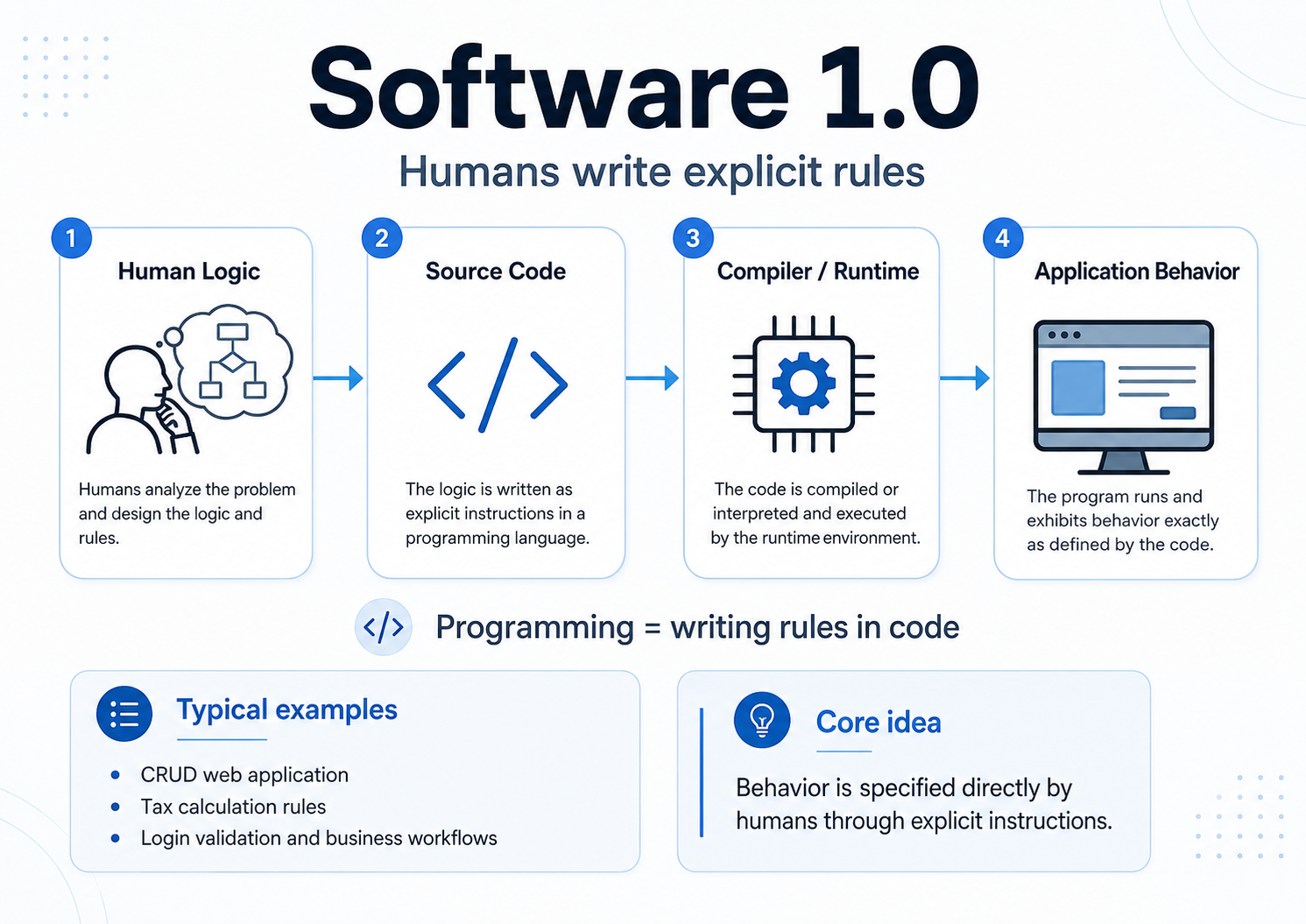
In this world, programming means writing rules in code.
A tax calculation, login workflow, CRUD application, batch job, payment validation rule, or business process engine follows this pattern. The behavior of the system is directly specified by humans. If the requirement changes, the code changes. If the behavior is wrong, engineers inspect the code path, test case, configuration, dependency, or deployment that produced it.
The core idea:
Behavior is specified directly by humans through explicit instructions.
Software 2.0: Models Learn from Data
Software 2.0 changed the control surface.
Instead of writing every rule directly, humans collect data, define labels or objectives, choose model architectures, train models, and use learned weights to make predictions on new inputs.
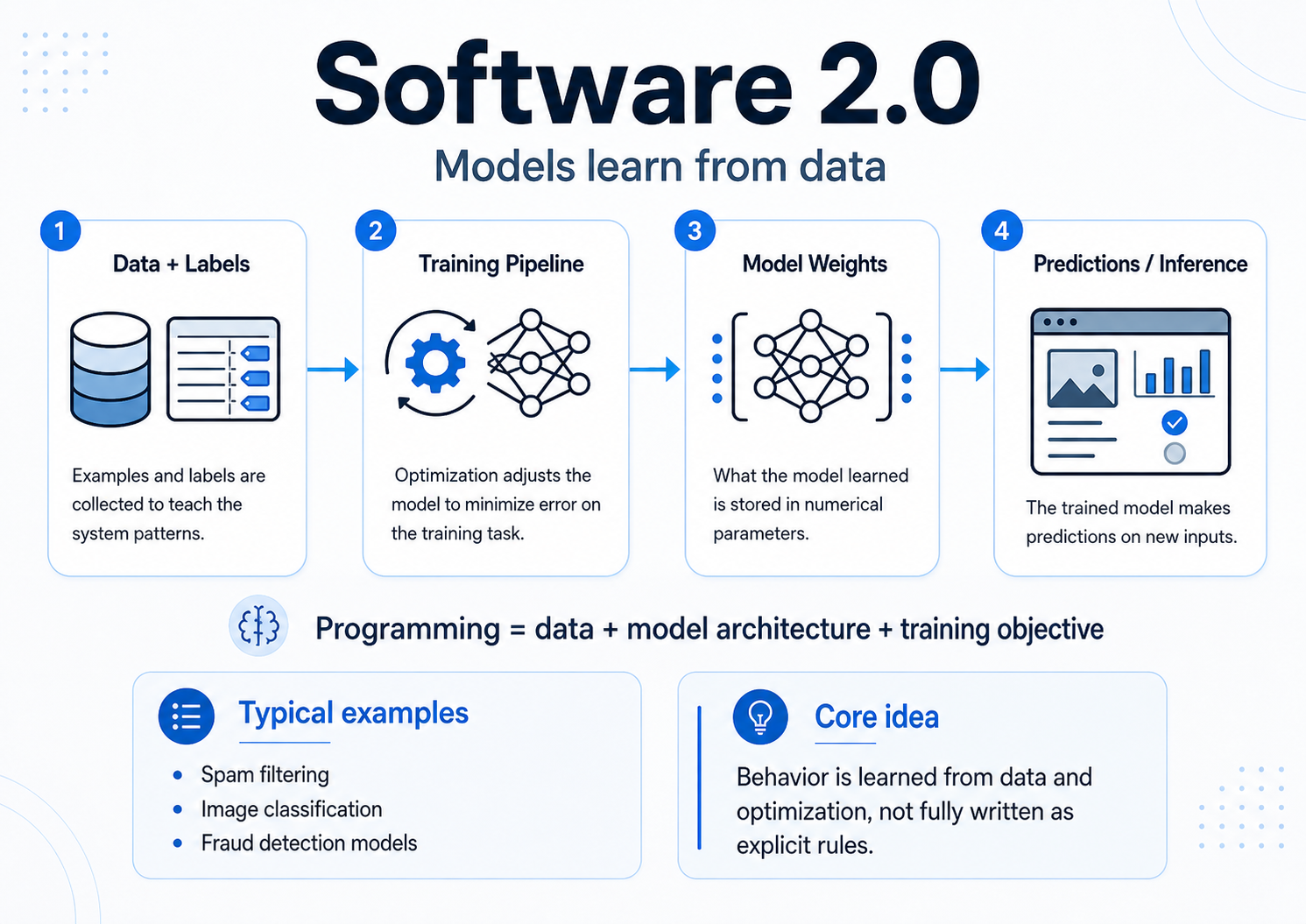
In this world, programming means shaping behavior through data, model architecture, and a training objective.
Spam filtering, image classification, fraud detection, recommendations, credit-risk scoring, ranking systems, and anomaly detection often follow this pattern. Humans do not write every decision rule by hand. They define the conditions under which the system learns.
This introduced a different engineering discipline: data quality, training pipelines, feature engineering, model validation, drift monitoring, explainability, bias testing, and governance.
The important lesson from Software 2.0 was this:
When behavior is learned, engineering control moves upstream into data and downstream into validation.
You cannot manage a learned system only by reading code. You have to understand the data it learned from, the objective it optimized for, the environment it runs in, and the monitoring that tells you when it is going stale.
Software 2.0 made software less deterministic from the outside.
Software 3.0 goes further: it gives the model tools.
Software 3.0: Models Act Through Context, Tools, and Feedback
Software 3.0 changes the control surface again.
Now the model is not only making a prediction. It can reason over context, call tools, generate code, search documents, inspect logs, update files, call APIs, create tickets, trigger workflows, and collaborate with other agents.
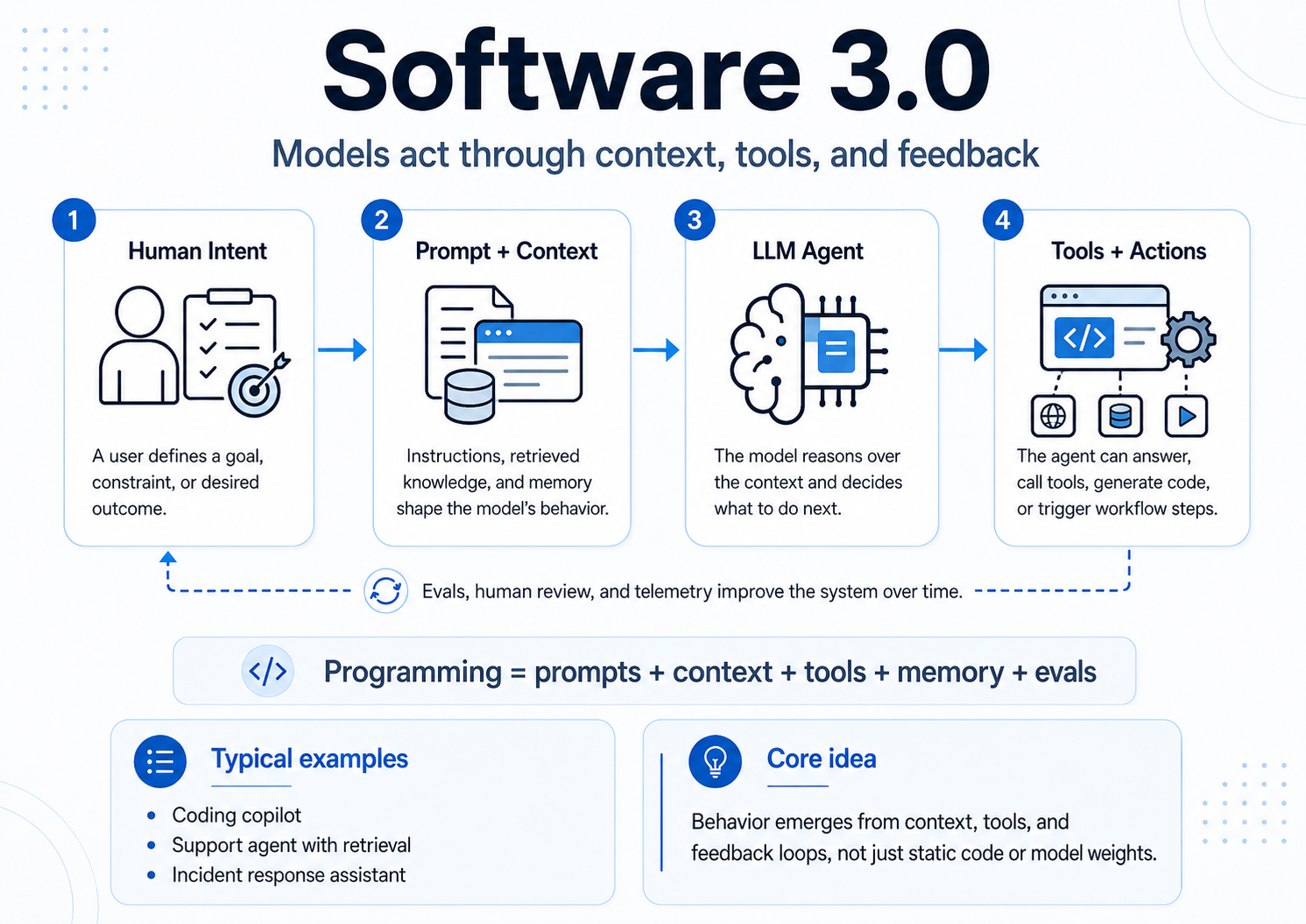
In this world, programming becomes:
prompts + context + tools + memory + evals + guardrails
Code does not disappear. It becomes one part of a broader behavioral system.
The model’s behavior may depend on the system prompt, user request, retrieved documents, tool descriptions, prior messages, saved memory, available APIs, permissions, examples, evaluation feedback, human review, and runtime telemetry.
Anthropic describes this broader discipline as context engineering: the work of curating and maintaining the right information available to the model at inference time, including instructions, tools, external data, and other state that may influence behavior (Anthropic, 2025a).
That is a major shift.
A prompt is no longer just a prompt.
It is part of the runtime environment.
From Prompt Magicians to Agentic Engineers
The shallow interpretation of Software 3.0 is that everyone needs to become a prompt engineer.
That interpretation is too small.
Prompting matters, but prompt skill alone does not make an AI system production-grade. A good prompt can produce an impressive demo, scaffold an application, summarize a document, or generate a useful response. But production systems require more than useful responses. They require reliability, security, observability, evaluation, recovery, and accountability.
The real call to action is not for every developer, architect, or engineering leader to become a prompt magician.
The real call to action is to build expertise in agentic engineering.
Agentic engineering is the discipline of designing, testing, securing, observing, and improving workflows where AI agents perform meaningful work through context, tools, memory, evaluations, guardrails, and feedback loops.
This is similar to the way software engineering became more than programming.
Programming is the act of writing code. Software engineering is the broader discipline of turning code into reliable systems through architecture, testing, deployment, security, maintainability, observability, and operations.
The same distinction now applies to AI-native systems.
Prompting is the act of instructing a model. Agentic engineering is the broader discipline of turning model behavior into reliable systems.
That distinction matters.
In traditional software engineering, professional teams do not stop at “the code works on my machine.” They build test suites, deployment pipelines, logging, monitoring, rollback procedures, access controls, architecture standards, and operational playbooks.
In agentic engineering, professional teams should not stop at “the model gave a good answer.” They need eval suites, scoped tools, context boundaries, memory policies, telemetry, approval gates, prompt-injection defenses, audit trails, and recovery paths.
Anthropic’s guidance on building effective agents emphasizes simplicity, composability, clear success criteria, feedback loops, and meaningful human oversight rather than unnecessary framework complexity (Anthropic, 2024). Karpathy makes a similar distinction between “vibe coding” and “agentic engineering,” where vibe coding raises the floor for software creation, while agentic engineering raises the ceiling for professionals building serious systems (Karpathy, 2026).
Software 3.0 does not eliminate engineering discipline.
It expands it.
Evals Become the New Control Plane
The reason coding agents are improving quickly is not only that models are better.
Coding has feedback.
Code can run. Tests can pass or fail. Diffs can be reviewed. Type checks can catch mistakes. Benchmarks can measure progress. Production incidents can be traced.
That gives engineering leaders a practical lesson:
The best early agentic workflows are the ones that can be verified.
A workflow is a stronger candidate for agentic automation when the task is bounded, the desired output is clear, the agent has access to the right context, the tool actions are constrained, success can be measured, failure can be detected, and bad actions can be reviewed or rolled back.
In Software 1.0, tests checked whether code met expectations.
In Software 3.0, evals check whether agent behavior meets expectations.
That means evals are no longer just a QA artifact. They become a design tool, governance tool, and release gate.
NIST’s AI Risk Management Framework frames AI risk management around governance, mapping, measurement, and management across the AI lifecycle. It also emphasizes that trustworthy AI systems must be valid and reliable, safe, secure and resilient, accountable and transparent, explainable and interpretable, privacy-enhanced, and fair with harmful bias managed (National Institute of Standards and Technology, 2023).
For an enterprise AI agent, evals should include happy paths, edge cases, ambiguous requests, adversarial prompts, missing-context scenarios, tool failure scenarios, permission-boundary tests, regression tests for prior failures, and human review samples.
Without evals, teams are not engineering agentic systems.
They are hoping.
Tools and Context Become Architecture
In traditional software, APIs are contracts between deterministic systems.
In agentic software, tools become contracts between deterministic systems and non-deterministic agents.
Anthropic describes tools as a new kind of software contract between deterministic systems and non-deterministic agents. The same tool may be called, ignored, misunderstood, or misused depending on the agent’s reasoning path. It recommends building and testing prototypes, creating comprehensive evaluations, choosing the right tools, namespacing them, returning meaningful context, and optimizing tool responses for token efficiency (Anthropic, 2025b).
That means tool design becomes a first-class engineering discipline.
A good agentic tool should have a clear purpose, narrow action boundary, meaningful name, well-described contract, high-signal output, safe defaults, explicit permission requirements, predictable error behavior, and enough context for the agent to decide what to do next.
The goal is not to expose every API to the agent.
The goal is to expose the right capabilities in a form the agent can use safely.
For example, an incident-response assistant should not receive unrestricted access to every log stream, deployment control, and ticketing action. It should receive scoped tools such as:
search_recent_errorssummarize_incident_contextidentify_recent_deploymentsdraft_incident_updaterecommend_rollback_candidaterequest_human_approval_for_rollback
Context deserves the same discipline.
The model only acts on what it can see. But giving it more information is not always better. Many teams will assume that better AI means dumping more data into the context window. That is usually not architecture. It is clutter.
A strong agentic system defines the context required for the task, the context retrieved dynamically, the context summarized, the context excluded, the context persisted as memory, and the context allowed to expire.
Prompting is what you say to the model.
Context engineering is the world you place the model inside.
Agentic engineering is how you make that world safe enough to operate.
Security, Trust, and Regulated Enterprise Adoption
A chatbot that gives a bad answer creates one kind of risk.
An agent that can take action creates another.
Once a model can call tools, generate code, query internal data, update tickets, create pull requests, send emails, modify configurations, or trigger operational workflows, security is no longer only about filtering input and output.
Security becomes action governance.
OWASP’s Top 10 for Large Language Model Applications identifies risks directly relevant to agentic systems, including prompt injection, insecure output handling, sensitive information disclosure, insecure plugin design, excessive agency, and overreliance (OWASP Foundation, 2025a). Prompt injection is especially important because agents often consume external content from files, websites, tickets, emails, documentation, and retrieved knowledge. OWASP notes that prompt injection can manipulate model behavior through direct or indirect inputs (OWASP Foundation, 2025b).
For enterprise teams, especially in regulated environments, the security model must be designed around what the agent can access, what it can change, and what controls exist around those actions.
A production-grade agentic system needs identity and access management, least-privilege tool permissions, approval gates for high-risk actions, secrets isolation, data classification rules, prompt-injection defenses, audit logs, traceability, rollback procedures, and incident-response playbooks.
The industry is moving quickly, but trust is not keeping pace. Gartner predicted that more than 40% of agentic AI projects will be canceled by the end of 2027 because of escalating costs, unclear business value, or inadequate risk controls (Gartner, 2025). Stack Overflow’s 2025 Developer Survey found that 87% of respondents were concerned about the accuracy of AI agents, and 81% had concerns about security and data privacy when using AI agents (Stack Overflow, 2025).
That is the gap engineering leaders need to close.
The answer is not to tell teams to “trust AI more.”
The answer is to build systems where trust is earned through design.
In a bank, healthcare system, insurance company, or other regulated enterprise, Software 3.0 cannot mean “let every team wire agents into production.” It has to mean disciplined experimentation with clear operating boundaries.
The first serious agentic workflows should have known data sources, limited action space, clear business value, verifiable outputs, recoverable failure modes, human review points, auditability, and low blast radius.
Do not organize AI adoption around demos.
Organize it around controlled autonomy.
The Agentic Engineering Operating Model
Here is a practical way to think about the operating model.
| Layer | Leadership Focus | Example Control |
|---|---|---|
| Intent | Define the work the agent is responsible for | Clear task boundary |
| Context | Control what the model can see | Curated context package |
| Tools | Limit what the agent can do | Scoped tool contracts |
| Memory | Manage what persists over time | Memory lifecycle policy |
| Evals | Measure behavior before release | Golden tasks and regression tests |
| Guardrails | Prevent unacceptable behavior | Input, output, and tool guardrails |
| Security | Protect systems and data | Least privilege and approvals |
| Observability | Explain what happened | Traces, logs, audit events |
| Human Review | Preserve judgment where needed | Approval gates and escalation |
| Recovery | Contain and reverse harm | Rollback, quarantine, incident workflow |
This is where Software 3.0 becomes more than a slogan.
A team that only improves prompts may get better responses.
A team that improves the operating model gets better systems.
Closing Thought
The prompt magician optimizes the instruction.
The engineering leader designs the system around the instruction.
That system includes context, tools, memory, evals, telemetry, permissions, human review, and recovery paths.
Software 3.0 does not remove the need for engineering leadership. It raises the standard for it.
The scarce skill is no longer memorizing every API or writing every line by hand. The scarce skill is knowing what should be built, what should be verified, what should be constrained, what should be observed, and when the system is off the rails.
The next generation of software organizations will not be defined by who uses AI the most.
They will be defined by who builds the best systems around AI.
The model matters.
But so does the environment around the model: the context, tools, memory, evals, telemetry, security model, review process, and feedback loop.
That is the real work of Software 3.0.
And it is leadership work.
References
Anthropic. (2024, December 19). Building effective agents. Anthropic. https://www.anthropic.com/research/building-effective-agents
Anthropic. (2025a, September 29). Effective context engineering for AI agents. Anthropic. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Anthropic. (2025b, September 11). Writing effective tools for agents — with agents. Anthropic. https://www.anthropic.com/engineering/writing-tools-for-agents
Gartner. (2025, June 25). Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027. Gartner Newsroom. https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
Karpathy, A. (2026, April 30). Sequoia Ascent 2026 summary. Bear Blog. https://karpathy.bearblog.dev/sequoia-ascent-2026/
National Institute of Standards and Technology. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). U.S. Department of Commerce. https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
OWASP Foundation. (2025a). OWASP Top 10 for Large Language Model Applications. OWASP. https://owasp.org/www-project-top-10-for-large-language-model-applications/
OWASP Foundation. (2025b). LLM01:2025 Prompt injection. OWASP GenAI Security Project. https://genai.owasp.org/llmrisk/llm01-prompt-injection/
Stack Overflow. (2025). 2025 Developer Survey: AI. Stack Overflow. https://survey.stackoverflow.co/2025/ai